Unlocking Advanced AI: RAG Capabilities in Vertex AI and the Evolution to Agentic RAG
This deep dive explores the sophisticated capabilities for Retrieval Augmented Generation (RAG) within Google Cloud's Vertex AI, followed by a critical comparison between the foundational Traditional RAG and the evolving, more dynamic approach of Agentic RAG.
1. Vertex AI: Your Foundation for Powerful RAG Applications
While there isn't a singular, monolithic "RAG engine" product, Google Cloud's Vertex AI delivers an unparalleled, comprehensive suite of services and tools. This modular ecosystem empowers developers to build, deploy, and scale highly effective Retrieval Augmented Generation (RAG) applications, offering supreme flexibility to match any complexity or scale requirement.
The primary services and approaches for RAG on Vertex AI include:
Vertex AI Search (formerly Enterprise Search / Generative AI App Builder):
The fastest path to enterprise RAG solutions. Vertex AI Search is a fully managed service designed to make your enterprise data instantly searchable and conversational.
How it works:
Effortless Data Ingestion & Indexing: Seamlessly connect diverse data sources (websites, documents, databases, structured and unstructured data). Vertex AI Search automatically processes, chunks, and creates embeddings for your content.
Intelligent Retrieval: When a user query arrives, it performs sophisticated semantic search against the indexed data to pinpoint the most relevant passages or documents.
Grounded Generation: It then leverages Google's cutting-edge foundation models (like Gemini) to generate a grounded response, crucially attributing sources for trustworthiness.
Benefits: Accelerated Development & Managed Scale: Eliminates the heavy lifting of infrastructure management, simplifying RAG solution deployment. Grounded & Attributed Responses: Automatically provides contextually accurate and source-attributed answers, minimizing hallucinations. Versatile Application: Ideal for rapid development of enterprise search, conversational AI, and sophisticated chatbot solutions.
Vertex AI Vector Search (formerly Matching Engine):
For granular control and unmatched performance in custom RAG pipelines. If your RAG solution demands precise control over embeddings, indexing, and retrieval strategy, Vector Search is your high-performance vector database of choice.
How it works:
Custom Embedding Generation: You generate embeddings for your data using Vertex AI's text embedding models (or other specialized models).
Optimized Vector Indexing: Store these embeddings in Vertex AI Vector Search, which builds a highly efficient index for lightning-fast similarity search.
Precision Retrieval: When a query comes in, you embed the query and leverage Vector Search to find the nearest neighbors (most similar data chunks) with unparalleled speed.
Seamless LLM Integration: The retrieved context, along with the original query, is then seamlessly passed to a Vertex AI foundation model (e.g., gemini-pro, text-bison) for sophisticated generation.
Benefits: Unparalleled Flexibility & Control: Offers granular command over embedding generation, indexing strategies, and retrieval mechanics. High-Performance Scalability: Powers real-time, large-scale semantic search for even the most demanding applications. Tailored Solutions: Cost-effective for crafting highly customized and optimized RAG scenarios.
Vertex AI Gen AI Studio / Foundation Models (e.g., Gemini, PaLM):
These powerful models serve as the intelligent core (the 'Generation' component) of any RAG system. Post-retrieval (from Vertex AI Search or Vector Search), the context is dynamically incorporated into prompts and fed to these models.
Vertex AI provides robust API access to these models, empowering developers to integrate them flawlessly into their custom RAG workflows.
Vertex AI Tools (e.g., Document AI):
For RAG systems designed to extract intelligence from complex, unstructured data (e.g., PDFs, scanned documents, images), services like Document AI are indispensable. They pre-process and transform raw, unstructured content into structured, searchable information, significantly enhancing retrieval accuracy and quality.
Extending Reach: Seamless Integration with Open-Source Frameworks (LangChain, LlamaIndex):
Vertex AI doesn't operate in isolation; it offers seamless integration with leading open-source frameworks like LangChain and LlamaIndex. This synergy empowers developers to leverage sophisticated abstractions and pre-built components for complex RAG pipelines—including advanced retrieval, intelligent chunking, and agentic capabilities—all while harnessing Vertex AI for foundational services.
In essence, Vertex AI stands as a robust, versatile platform, offering both the foundational components and the advanced tools necessary to architect, deploy, and scale RAG solutions ranging from straightforward to hyper-customized and intelligent.
2. The RAG Evolution: Traditional vs. Agentic Paradigms
The landscape of Retrieval Augmented Generation (RAG) is undergoing a profound transformation. While Traditional RAG laid the essential groundwork for grounding Large Language Models (LLMs), Agentic RAG marks a significant leap forward—a dynamic paradigm shift that empowers LLMs to orchestrate complex tasks through advanced reasoning and strategic tool utilization.
Here's a critical comparison:
2.1. Traditional RAG (Basic RAG)
Definition: Traditional RAG, also known as Basic RAG, defines a direct and linear approach. A user's query triggers the retrieval of pertinent information from an external knowledge base, which is then straightforwardly fed alongside the original query into a Large Language Model (LLM) to generate a response. This is often a single, fixed-step operation.
How it Works:
Embed Query: The user's query is converted into a vector embedding.
Retrieve Documents: This query embedding is used to search a vector database (containing embeddings of your knowledge base) for the most semantically similar documents/chunks.
Augment Prompt: The retrieved documents are concatenated with the original query and sent as context to the LLM.
Generate Response: The LLM generates a response based on the provided context and its internal knowledge.
Diagram:
User Query -> Embed Query -> Retrieve (Vector DB) -> Augment Prompt with Retrieved Docs -> LLM -> Response
Pros:
Ease of Implementation: Straightforward design makes it quicker to deploy.
Operational Efficiency: Typically involves fewer LLM calls, leading to lower latency and reduced operational costs.
Enhanced Factual Grounding: Significantly reduces LLM hallucinations by anchoring responses in verified external data.
Built-in Traceability: Facilitates source citation, boosting user trust and response verifiability.
Cons:
Constrained Reasoning: Struggles with multi-hop questions, requiring complex synthesis or iterative problem-solving.
Static Retrieval: The retrieval process is fixed; it cannot adapt based on the LLM's intermediate reasoning or dynamically refine its search.
Lack of Dynamic Adaptation: Unable to self-correct or seek additional information if initial retrieval is insufficient or incorrect.
Limited Tool Integration: Primarily confined to text retrieval; cannot natively leverage external tools like APIs, databases, or code interpreters.
Context Window Constraints: Still subject to the LLM's token limits, potentially forcing aggressive data chunking and risking loss of broader context.
Best Use Cases:
Simple Q&A from a defined knowledge base.
Efficient document summarization.
Rapid fact-checking of single statements.
Building basic chatbots with clearly delimited scopes.
2.2. Agentic RAG
Definition: Agentic RAG represents a transformative evolution, elevating the LLM from a passive generator to an intelligent, proactive "agent." This agent possesses the crucial ability to plan, execute multi-step processes, strategically utilize diverse tools (where RAG itself becomes a powerful component), engage in iterative reasoning, and dynamically self-correct based on feedback. It shifts from a rigid pipeline to a highly adaptive, LLM-orchestrated workflow.
How it Works (Illustrative Flow):
User Query: The agent (LLM) receives the initial query.
Planning/Thought: The LLM "thinks" about the best strategy to answer the query, breaking it down into logical sub-tasks.
Dynamic Tool Selection & Execution: Based on its sophisticated plan, the LLM intelligently decides which "tools" to employ. These tools can include:
RAG Tool: For retrieving specific information from a vector database.
API Tool: To interact with external services (e.g., weather API, CRM, financial data).
Code Interpreter Tool: To perform complex calculations or data manipulation.
Search Tool: To perform real-time web searches for current or broad information.
Observation & Iteration: The agent rigorously observes the outcomes of each tool execution.
Reflection & Refinement: The agent critically evaluates whether the results are sufficient. If not, it intelligently refines its plan, potentially utilizing different tools or re-querying with more specific parameters. This can involve multiple RAG calls or RAG calls interleaved with other tool uses, forming a dynamic loop.
Synthesized Response: Once satisfied, the agent synthesizes all gathered information into a comprehensive and accurate final response.
Diagram:

Pros:
Unleashed Reasoning Power: Masterfully handles complex, multi-hop queries and tasks demanding deep synthesis across varied information types.
Adaptive & Intelligent Workflow: Dynamically selects optimal strategies and tools based on the evolving query and intermediate observations.
Robust Self-Correction: Possesses the critical ability to detect and rectify errors or knowledge gaps, prompting further exploration or re-evaluation.
Seamless Tool Orchestration: Integrates RAG with a powerful arsenal of external tools (APIs, calculators, web search), dramatically expanding problem-solving capabilities.
Superior User Experience & Accuracy: Delivers exceptionally comprehensive, precise, and nuanced answers, even for the most challenging prompts.
Cons:
Heightened Design & Debugging Complexity: The non-linear, iterative nature makes development and troubleshooting significantly more intricate.
Increased Latency & Computational Overhead: Multiple LLM interactions and tool executions inherently lead to longer response times and higher computational demands.
Elevated Operational Costs: Each LLM call and tool invocation contributes to potentially substantially higher operational expenses.
Challenges in Predictability: The dynamic and adaptive reasoning paths can introduce non-determinism, making consistent outcome prediction more difficult.
Advanced Prompt Engineering Demands: Crafting effective prompts for orchestrating the agent's planning, execution, and reflection cycles requires specialized expertise.
Best Use Cases:
Complex, multi-hop question answering requiring information synthesis from disparate sources.
Automated research tasks demanding dynamic information gathering and analysis.
Sophisticated decision-making systems that must consult multiple data sources and tools.
Personal assistants capable of interacting with various applications and knowledge bases.
Scenarios where the LLM needs to perform calculations, query structured databases, or interact with external services.
2.3. Key Differences Summary
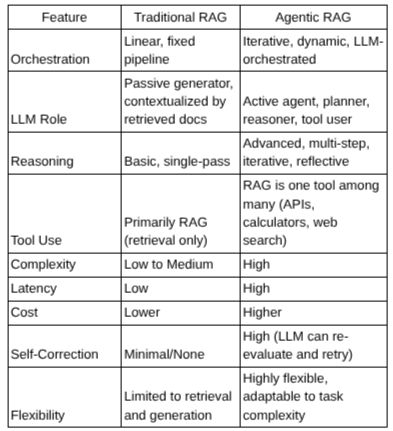
Why This Matters
The choice between Traditional and Agentic RAG depends on the use case. If you’re building a customer support chatbot, Traditional RAG may suffice. But if you're building a research assistant that autonomously navigates sources, performs analysis, and summarizes — Agentic RAG is your friend.
With tools like Vertex AI RAG Engine and Google's Agent Framework, these patterns are no longer confined to research labs — they’re ready for production at scale.